
Hi all, attached the latest draft of the presentation, comments welcome. I have especially added this section which further explains the idea on how to continue and make use of the taxonomy On 23.04.2017 22:44, Thorsten H. Niebuhr [WedaCon GmbH] wrote:
Hi Folks,
as you might know, one of the events during conference Season (EIC in Munich) will host (beside the Kantara Workshop) a 15 Minute Slot explaining the BoK Taxonomy (see https://www.kuppingercole.com/sessions/1921), I am currently working on this deck, stay tuned for a draft version this week! The presentation itself will focus on the taxonomy and the next steps to build the BoK, as well as what I am trying to explain in this exact mail here.
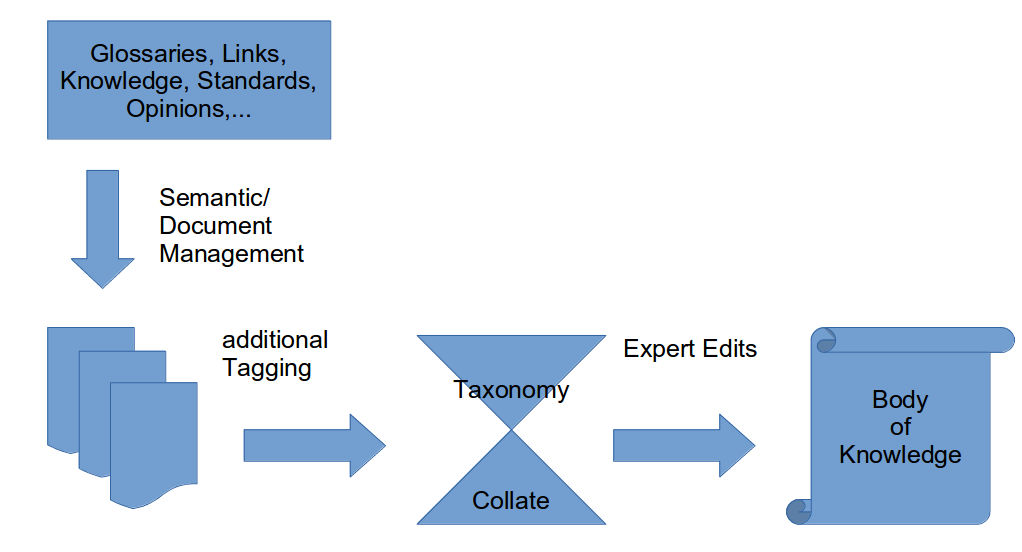
The taxonomy is the first milestone and the basis for the future work to create a Body of Knowledge for IDPro. Even though important, the road ahead to build this BoK is still not defined. To stay in this picture: With the taxonomy, we have defined the road. The final destination (a Body of Knowledge) is also somewhat defined.
But which vehicle should we use? How can we coordinate the work to build and define this Body of Knowledge, without getting into to too much in-fights and discussions, for example about what exactly an attribute is and what an identity might be good for? During the design and discussion on the taxonomy, we were (mostly) able to keep these discussions to a minimum. And I think we should still onlywithstand these approaches for now, and here is why:
This group (not only the subgroup for BoK, but all who signed the pledge and are actively contributing to the groups) is full of outstanding experts on the subject of matter. But I think we need more than this expertise.
What we need is the expertise and the knowledge on how to create a Body of Knowledge in *general*. We need experts who know how to channelize our proven knowledge in the subject matter (Identity and Access Management) into processes and procedures to create and maintain this knowledge base. We need Knowledge Management Experts, as much as we need experts in Identity and Access Management.
I do think that we can and should continue to collect articles, links, standards, viewpoints and whatever we can find (useful) for the subject matter. But we should not start now trying to sort and categorize them too deeply now.
Here is my proposal to drive it
* Create a simple Link/Document collection, which consist of *meta data* only o Link o Short description (max 200 Characters) o Release/ Document Date (Month/YEAR as YYYYMM) o Tagging for source (limited tagging), eg + Non-Profit Organization + Profit Organization + Personal (Blog or similiar) + Standards + Government/ legal
The attentive reader will realize that these details will not provide any way to link into our taxonomy. This will be the mission of the knowledge experts. The link on the bottom will provide you with an example on what *could* be done in the next step. It involves a semantic Knowledge management system, which is able to automatically tag, sort and contextualize information.
My vision is to feed such a system with our collections (taxonomy on one side, collections from the other side) and automatically generate a kind of 'knowledge (data)base' from this, which can also serve as input for any textual / editorial release for it. As I am not really a knowledge Management expert, and my experience with Semantic Technologies is also limited, I therefor propose to
* Reach out into the wild to get some support from Knowledge Management Experts on best ways to continue o Semantic Knowledge Management o others Knowledge Management Techniques o how to link/ aggregate and manage
To get an idea of my vision, I encourage you to check out the following links. I am not actively involved in that company in any way, its just one of those we are currently investigating in respect to semantic technologies.
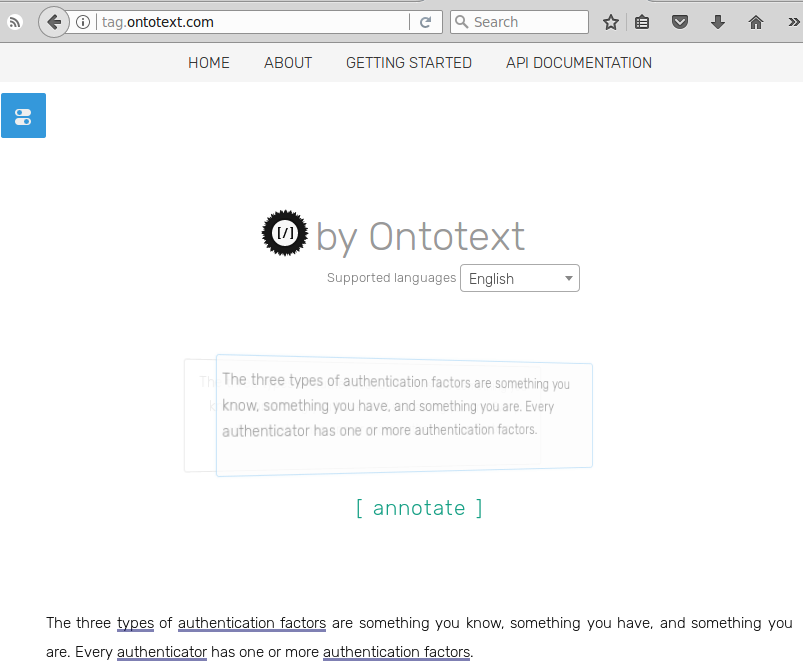
The service below is a demo for a semantic text analysis system. Just paste your text into the UI, and let the system analyze it. Remember: its a demo (but: a impressive one)
The text I have used is from NIST_800-63-3B : 'The three types of authentication factors are something you know, something you have, and something you are. Every authenticator has one or more authentication factors.'
Just paste this into 'http://tag.ontotext.com/' and press 'annotate', to get a feeling on this.
Looking forward to your comments and contributions, and a good start into the week!
Thorsten
P.S.: The first version of this mail defined the road as the missing part, and not the vehicle. Still undecided which to use....
--
Thorsten H. Niebuhr tniebuhr@wedacon.net / tniebuhr@wedacon.de <mailto:tniebuhr@wedacon.net>
WedaCon Informationstechnologien GmbH Office: +49 (251) 399 678-22 Fax: +49 (251) 399 678-50 Mobile: +49 (174) 991 257 4 Kroegerweg 29 D-48155 Muenster http://www.wedacon.net
Amtsgericht Muenster HRB 6115 USt.-ID: DE216758544 StNr.: 336/5775/1487 Geschaeftsfuehrender Gesellschafter: Thorsten H. Niebuhr
{kind=link}
{kind=link}